

Speaking Volumes
The world's frontier AI labs are racing toward voice interfaces. India has been building the training ground for a decade without knowing it.

In 2017, the Wall Street Journal wrote a story about a porter at New Delhi’s railway station. Megh Singh, the porter, earned less than eight dollars a day, had never sent an email and was not comfortable with a keyboard. He was using voice search on YouTube to find Rajasthani folk songs in Hindi, sending recorded messages to his family on WhatsApp and downloading video clips to watch at night. “We are enjoying the internet to the fullest,” he told the publication.
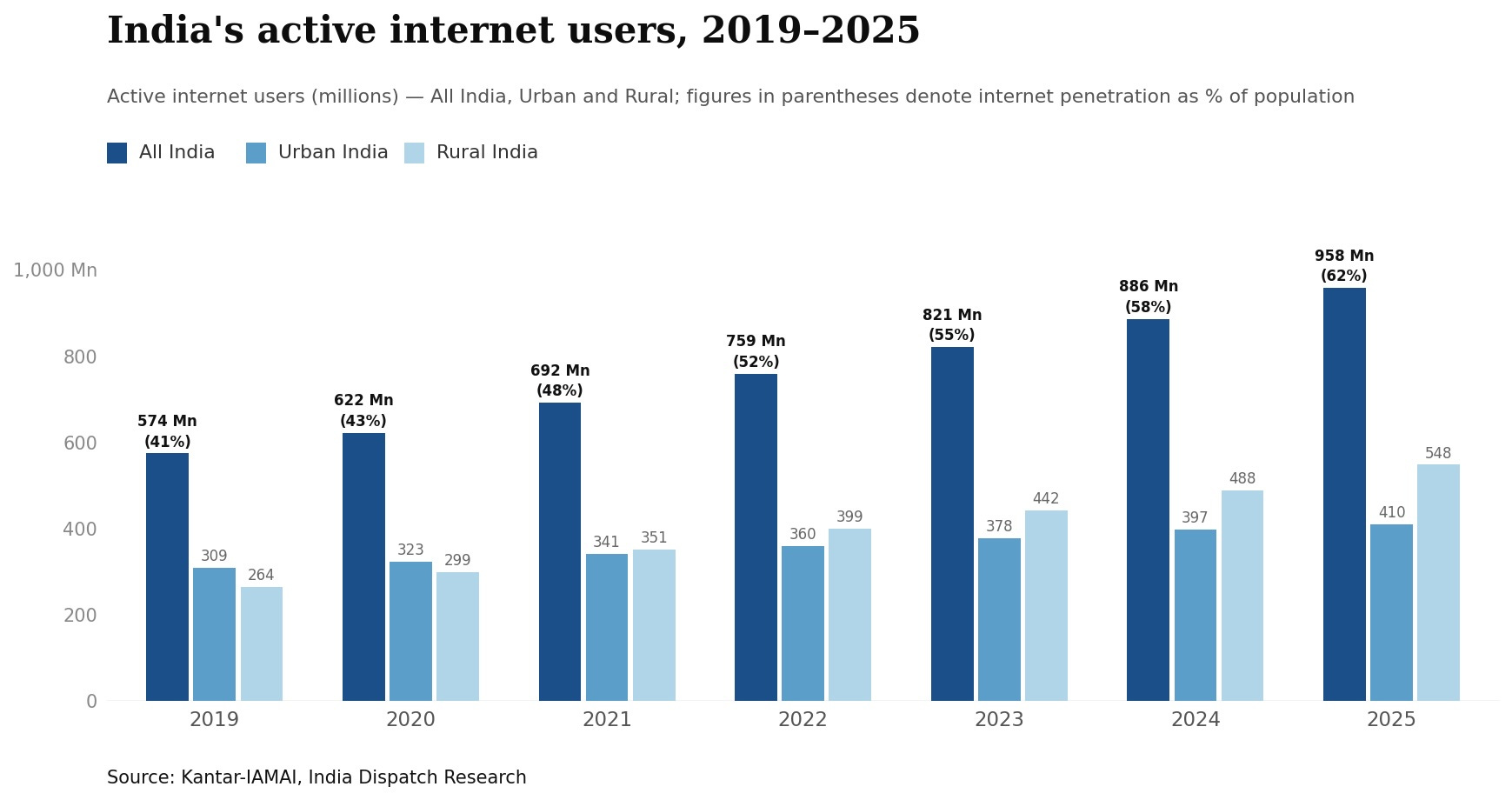
The 400 million Indians who were online that year have since grown to over 950 million, per IAMAI and Kantar, and one in five of them now navigates the internet by voice. That number, and what it represents in accent, dialect, language-switching and real-world deployment scale, is what could finally position India at the centre of an AI boom it has largely watched from the outside.
India has mostly been written off in the AI conversation the past three years. Its equity markets sat out the global rally, its indices dominated by banks and consumption companies with no stake in the GPU buildout reshaping markets in the US, Taiwan, South Korea and Japan. Indian IT services employs roughly 5.8 million people and generates an outsized share of corporate India’s profits. When Anthropic released tools that could automate back-office work and modernise COBOL code, Indian IT stocks lost nearly 15% in a month and TCS fell below a market cap it had not seen since 2020. That disruption may have been priced in accurately, but what the market was not pricing was where India sits in the layer of AI that is growing fastest.
Nearly $380 billion in investment pledges have been made toward India’s AI ecosystem this year. Of that, roughly $260 billion is allocated to energy and $115 billion to data centres and networks. The AI model layer has $1.5 billion assigned to it. Another $1.5 billion is earmarked for applications. India generates nearly 20% of the world’s data but holds only 3% of global data centre capacity. The private market is beginning to make a different bet on where value will actually accumulate.
The mismatch that matters most for voice AI is not between languages but mediums. English accounts for 49.5% of websites with a known content language and Hindi for under 0.1%. Yet 870 million Indians accessed the internet in Indic languages in 2024, and among Indic-language internet activity the dominant uses were watching videos and listening to music, not typing queries into websites. The global training corpus is missing not only the language but the way India actually uses the internet.
India’s BPM sector employs 1.65 million workers in call centres, payroll and data handling and accounts for 52% of the global outsourcing market. The country has been running voice-saturated enterprise workflows at scale for two decades, and that history is also a speech-data history.
The most concrete evidence of what that means commercially came from Bajaj Finance’s Q3 FY26 earnings call. Managing director Rajeev Jain told analysts that AI had listened to 20 million customer calls, converted voice to text and generated 100,000 new loan offers for customers the company previously lacked data on. Disbursements through AI-powered call centres came in at $172 million, 10% of the company’s total disbursals that quarter. Jain called it “just our first attempt” and said the company expects to process 100 million AI-powered calls in the coming year. Bajaj Finance did not build a new product but extracted value that had already existed, unread, in two decades of recorded customer conversations.
UPI 123PAY lets India’s roughly 400 million feature-phone users make payments through IVR calls and missed calls without internet access, in 12 Indian languages. BHASHINI has been wired into Indian Railways for multilingual voice assistants across public platforms. BHASHINI supports about three dozen languages across more than 1,600 AI models and processes millions of inferences daily. The government’s CPGRAMS grievance system now accepts complaints by voice in 22 regional languages.
A speaker’s accent, their habit of switching between Hindi and English mid-sentence and the way a language sounds when it is someone’s only tongue rather than a second one learned in school do not survive into a text corpus. Researchers who built a Hindi speech recognition benchmark drawing on 132 speakers from 83 districts found that mainstream commercial and open-source systems broke down badly across India’s accent regions, and worse still on names, places and domain-specific words. Hindi in one part of the country sounds different from Hindi in another part, and the training data that exists does not reflect either very well.
Hinglish, the Hindi-English mixing that characterises hundreds of millions of everyday conversations, produces roughly 42% word error rate on baseline monolingual-trained models. Publicly available code-switched datasets remain scarce. Small amounts of dialectal fine-tuning can outperform much larger quantities of standard-language data.
Building speech systems that actually work in India requires collecting data the way field researchers do, district by district, speaker by speaker. AI4Bharat’s speech effort spans over 400 districts and covers 300,000 hours of raw speech, 6,000 hours of transcribed data and 6,400 hours of mined audio-text pairs. Its IndicVoices dataset drew spontaneous and conversational speech from 51,000 speakers across 400 districts in 22 languages, released under an open license for research and commercial use.
Meesho launched Vaani, a generative AI voice shopping assistant aimed at tier-2 and tier-3 users who find typing-based e-commerce unintuitive, and within its first month 1.5 million users had tried it, conversion rates ran 22% higher than regular browsing and return rates fell. In India, where shopping has always been conversational, the assistant replicates what a kirana shopkeeper does — listens, asks follow-up questions and guides the buyer to a decision.
Sarvam dubbed the Union Budget 2026 live in Kannada and Hindi on Republic TV, the first national budget to be dubbed live using AI. The Prime Minister’s monthly address is dubbed every month into 11 Indian languages using Sarvam’s system while preserving the speaker’s voice. In India, dubbing is how content crosses the language market at all.
ElevenLabs closed 2025 with $330 million in annual recurring revenue and raised $500 million at an $11 billion valuation in February 2026. India is already its second-largest enterprise market globally, ahead of markets it has operated in far longer. Usage in India surged 50% in the three months ending January 2026, and the company has set an India revenue target of $100 million, deploying its technology with enterprises including Meesho, TVS Motor, Mahindra and PocketFM.
Every company building the next generation of voice AI needs training data in the languages users actually speak, across the accents, dialects and code-switching patterns of real conversations. That data does not exist in any web corpus. It only accumulates inside actual deployments, and India has more of those deployments, running at greater scale and in more linguistic variety, than anywhere else.
Megh Singh was producing a version of it in 2017, a Hindi voice query on a railway station’s free Wi-Fi that trained nothing and went nowhere. The infrastructure to catch what came next has since been assembled without design: in call centres logging two decades of customer conversations, in a research lab collecting speech from 51,000 speakers across 400 districts, in payment and grievance systems processing hundreds of millions of voice interactions a year.
India was written off because the AI boom was about text, chips and data centres. The boom in voice AI is about something else entirely, and India has more of it than anywhere else.